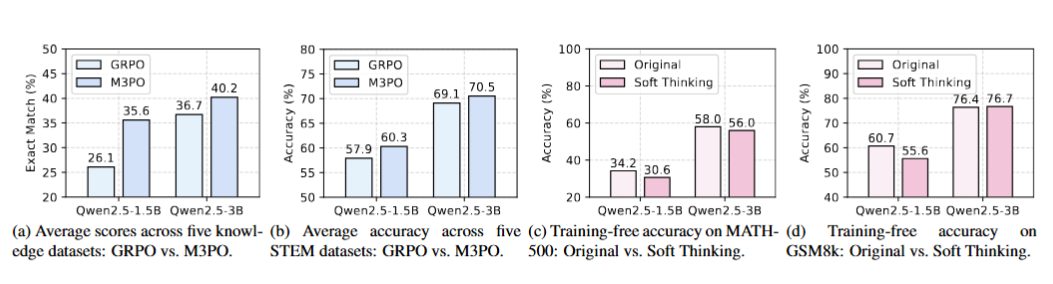
Figure 1: Comparative analysis of reasoning paradigms. M3PO consistently improves performance on knowledge and reasoning benchmarks compared to Soft Thinking and standard CoT.
Chain-of-Thought (CoT) reasoning has significantly advanced the problem-solving capabilities of Large Language Models (LLMs), yet conventional CoT often exhibits internal determinism during decoding, limiting the exploration of plausible alternatives. Recent methods attempt to address this by generating soft abstract tokens to enable reasoning in a continuous semantic space. However, we find that such approaches remain constrained by the greedy nature of autoregressive decoding, which fundamentally isolates the model from alternative reasoning possibilities.
In this work, we propose Multi-Path Perception Policy Optimization (M3PO), a novel reinforcement learning framework that explicitly injects collective insights into the reasoning process. M3PO leverages parallel policy rollouts as naturally diverse reasoning sources and integrates cross-path interactions into policy updates through a lightweight collaborative mechanism. This design allows each trajectory to refine its reasoning with peer feedback, thereby cultivating more reliable multi-step reasoning patterns. Empirical results show that M3PO achieves state-of-the-art performance on both knowledge- and reasoning-intensive benchmarks.
Figure 1: Comparative analysis of reasoning paradigms. M3PO consistently improves performance on knowledge and reasoning benchmarks compared to Soft Thinking and standard CoT.
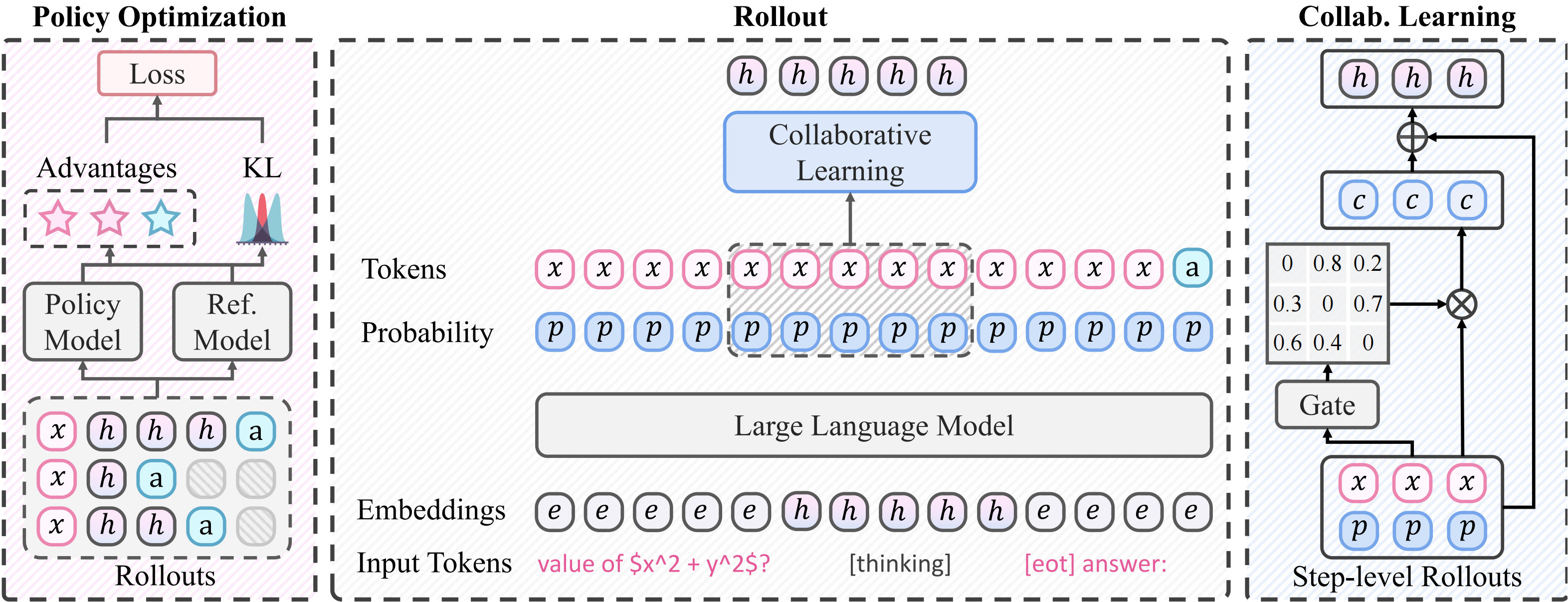
Figure 3: Overview of the M3PO framework.
The M3PO framework establishes a closed-loop optimization process that seamlessly integrates multi-path reasoning with a step-level collaborative mechanism. As illustrated in Figure 3 above, the framework comprises three core components:
Given an input question, the policy model generates $N$ parallel rollouts. These serve as naturally diverse independent reasoning sources, eliminating the need for curated auxiliary datasets.
A parameter-free gating function enables cross-path interaction. Trajectories refine their reasoning by incorporating "peer insights" from other paths based on distributional consistency.
Using group-relative advantage estimation, the policy is updated to reinforce refined reasoning patterns, internalizing robust logic without needing collaboration mechanisms at inference time.
Comparing GRPO vs M3PO on detailed benchmark datasets. M3PO consistently outperforms GRPO across both Knowledge and STEM domains.
Question: What is the ones digit of \( 22^{22 \cdot (11^{11})} \)?
@article{lv2025multi,
title={Multi-Path Collaborative Reasoning via Reinforcement Learning},
author={Lv, Jindi and Zhou, Yuhao and Zhu, Zheng and Wang, Xiaofeng and Huang, Guan and Lv, Jiancheng},
journal={arXiv preprint arXiv:2512.01485},
year={2025}
}